Architectural Description – Ea-2-Sa Local + Vectorized AI Implementation
1️⃣ Purpose and Scope
This architecture describes how the Ea-2-Sa Platform operationalizes local AI inference with vectorized memory using a hybrid deployment pattern. It translates the conceptual framework from Part 1 into a working reference implementation unifying:
- Local compute (Ollama) for inference close to the data.
- Managed vector memory (Pinecone) for contextual retrieval.
- API governance (Kong Gateway) for runtime policy and service mediation.
- Containerized infrastructure (Docker Compose) for portability and reproducibility.
The solution demonstrates how architectural intent becomes executable code — a cornerstone of Ea-2-Sa’s Architecture-as-Code philosophy.
2️⃣ Architectural Context
| Actor / Role | Description |
|---|---|
| Developer / Architect | Configures and deploys the local AI environment and consumes API endpoints. |
| Ollama Runtime | Local inference engine hosting open models such as Mistral 7B or Llama 3. |
| Pinecone Service | Managed vector database storing contextual embeddings for RAG. |
| Vector Proxy Service | Node.js microservice bridging Ollama and Pinecone for embedding and context fusion. |
| Kong Gateway | Provides ingress layer for service discovery, auth, and observability. |
| Redis Cache | Caches embedding and retrieval results for low-latency responses. |
3️⃣ Architectural Viewpoints
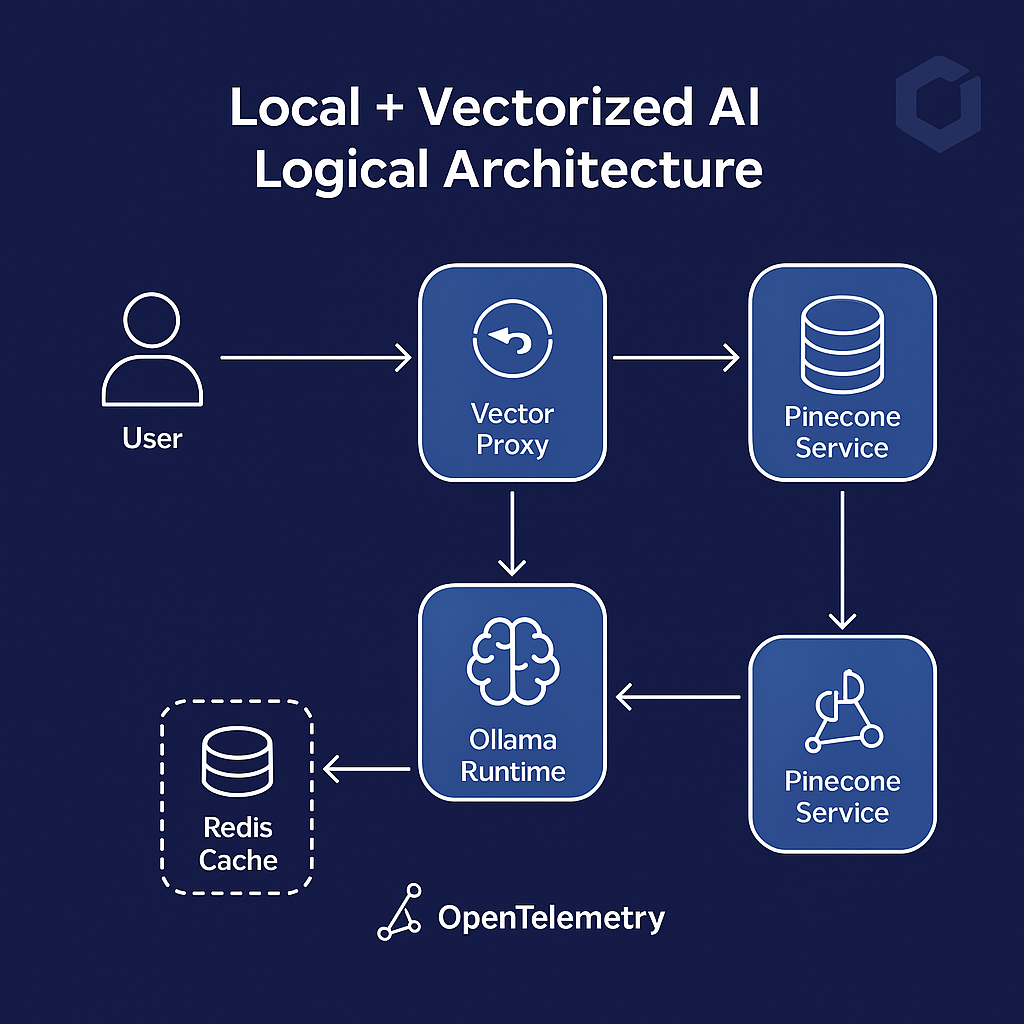
A. Logical View
User → Kong Gateway → Vector Proxy → Ollama Runtime → Pinecone Service
↘︎ Redis Cache (optional)
The Vector Proxy orchestrates requests between the local model and vector store, creating a lightweight RAG workflow. Kong enforces access control and telemetry across API interactions.
B. Deployment View
- Host Environment: Ubuntu 20.04 + Docker Engine
- Containers: Ollama, Vector-Proxy, Redis, Kong
- External Services: Pinecone API (Managed SaaS)
- Connectivity: All services share an isolated Docker network
ea2sa-net.
C. Data Flow
- User submits a prompt via
/api/ai/infer. - Kong validates API Key / JWT and routes to Vector Proxy.
- Proxy embeds the input and queries Pinecone for context vectors.
- Combined context + prompt sent to Ollama for local inference.
- Result cached in Redis and returned to the client.
- Metrics emitted via OpenTelemetry → Prometheus.
4️⃣ Technology View
| Layer | Technology | Function |
|---|---|---|
| Compute / Model | Ollama Runtime | Executes open-source LLMs locally. |
| Memory / Knowledge | Pinecone Index | Stores embeddings and retrieves context vectors. |
| Integration / Control | Kong + Vector Proxy | Orchestrates traffic, policy, and embedding logic. |
| Observability | OpenTelemetry + Prometheus | Collects metrics and exposes health. |
| Storage / Cache | Redis | Provides low-latency recall of frequent queries. |
5️⃣ Security & Governance
- Identity & Access: Kong Key-Auth / JWT plugins enforce token-based security.
- Data Protection: No external transmission of proprietary data; inference and caching stay internal.
- Auditability: OpenTelemetry traces align with SAFe’s Inspect & Adapt cycle.
- Configuration Management: Docker Compose + YAML in version control ensure immutability and traceability.
6️⃣ Quality Attributes
| Attribute | Design Mechanism |
|---|---|
| Scalability | Horizontal container scaling or additional Pinecone pods. |
| Resilience | Healthchecks + Redis cache handle temporary Pinecone outages. |
| Portability | Consistent runtime across dev/staging/prod with Docker Compose. |
| Observability | OpenTelemetry metrics exposed to Prometheus. |
| Security | JWT tokens + TLS termination at Kong. |
| Maintainability | Modular microservices + declarative YAML configurations. |
7️⃣ Alignment with TOGAF & SAFe
| Framework | Corresponding Element |
|---|---|
| TOGAF – Application Layer | Ollama Runtime & Vector Proxy |
| TOGAF – Data Layer | Pinecone Indexes & Redis Cache |
| TOGAF – Technology Layer | Docker Network + Kong Gateway |
| SAFe – Portfolio Level | Strategic Theme: AI Enablement |
| SAFe – Program Level | Features: AI Pipeline Deployment, AI Governance Integration |
| SAFe – Team Level | User Stories for container config, API testing, metric setup |
8️⃣ Architectural Summary
This architecture embodies Ea-2-Sa’s principle of architectural traceability — every container, route, and configuration maps to a business capability. Local AI inference ensures sovereignty and cost efficiency; vectorized memory enables contextual reasoning; and declarative infrastructure delivers repeatable, governable deployment.
Outcome: A reproducible, secure, and observable Local + Vectorized AI environment aligned with enterprise architecture standards.
Next in this series → Part 3 – AI Governance & Compliance Automation.
📘 Download the Article